Czym jest Event Sourcing?
To wzorzec projektowy, w którym operacje biznesowe zapisujemy jako zdarzenia w bazie danych (sekwencja zdarzeń), stanowi to odejście od tradycyjnego modelu przchowywania tylko bieżącego stanu danych aplikacji.
Aby uzyskać aktualny stan encji/agregatu w ES (ang. Event Sourcing) należy zagregować/zsumować sekwencję powiązanych ze sobą zdarzeń.
TIP
Pojęcia encji i agregatu będę używał zamiennie, ale warto podkreślić że są to odmienne byty.
Encja to obiekt domenowy posiadający tożsamość (tzn. posiada identyfikator)
Agregat to zbiór powiązanych encji i obiektów wartości, reprezentujący jedną spójną jednostkę biznesową, z jednym publicznym punktem dostępu - korzeniem agregatu. Agregat egzekwuje reguły i spójność, a encje są jego elementami.
Jak już wspomniałem, ES to alternatywny sposób przechowywania danych. W klasycznym podejściu zorientowanym na stan przechowujemy tylko bieżącą wersję encji, podczas gdy ES przechowuje każdą zmianę, dzięki czemu możemy przejść przez dowolny moment z cyklu życia encji. Nie zatracając przy tym żadnej informacji.
Zanim przejdziemy do bardziej szczegółowego omówinia ES, wspomnijmy jeszcze czym nie jest ES, aby nie mylić go z innymi zagadnieniami.
Czym NIE jest Event Sourcing?
Ze względu na podobieństwo terminów warto podkreślić, że ES to nie to samo co:
Event Storming
Jest to metoda umożliwiająca szybkie i skuteczne zidentyfikowanie potrzeb biznesowych wystepujących w konkretnej domenie. Sama metoda odbywa się w formie warsztatów, w których uczesticzą osoby techniczne (programiści, architekci oprogramowania), eksperci z danej domeny (interesariusz/klient biznesowy; np. związany z finansami, medycyną itd.) i oczywiście osoba prowadząca same warsztaty.
Metoda podzielona jest na kilka etapów, w których na tablicy zamieszczamy karteczki z odpowiednimi kolorami i opisami. Wyróżnić możemy 4 główne kroki:
- Identyfikujemy zdarzenia (events) w systemie opisujemy je bizensowo a nie technicznie.
- Identyfikujemy polecenia (commands), które mają wyzwalać poszczególne zdarzenia.
- Identyfikujemy aktorów, którzy wyzwalają poszczególne komendy.
- Grupujemy powiązane ze sobą elementy tworząc agregaty.
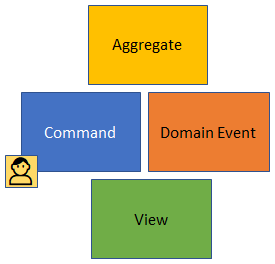
Przygotowana w ten posób tablica stanowi bardzo dobry punkt wejścia dla modelowania systemu informacyjnego przy pomocy DDD (ang .Domain Driven Design). To z kolei może być skutecznie wykorzystane do projektowania systemu opartego o wzorzec Event Sourcing, ponieważ Event Storming w podobny sposób definiuje granice dla swoich elementów, oraz definiuje bardzo zbliżone terminy. To owocuje dosyć łatwym przekładem wynikowej tablicy Event Stormingu na system oparty o Event Sourcing. Niemniej nadal są to różne zagadnienia i nie należy ich mylić.
Event Streaming
Event Streaming to praktyka rejestrowania i przetwarzania danych w czasie rzeczywistym, pochodzących z różnych źródeł - takich jak aplikacje, bazy danych, systemy biznesowe czy urządzenia IoT. Zamiast gromadzić duże porcje danych event streaming operuje na pojedynczych zdarzeniach w momencie ich wystąpienia.
Event streaming jest kluczowym elementem event-driven architectures (EDA) - architektur opartych na zdarzeniach. Pozwala tworzyć reaktywne, luźno powiązane systemy, w których komponenty komunikują się poprzez publikowanie i subskrybowanie zdarzeń, a nie poprzez bezpośrednie wywołania API.
Pojęcia Event Streaming i Event Sourcing mogą pojawiać się razem, ale oznaczają coś zupełnie innego:
| Cecha | Event Streaming | Event Sourcing |
|---|---|---|
| Cel | Przesyłanie i przetwarzanie zdarzeń w czasie rzeczywistym | Trwałe zapisywanie historii zmian stanu systemu poprzez dodawanie zdarzeń do magazynu |
| Charakter | Operacyjny, nastawiony na przepływ danych ("data in motion") | Historyczny, nastawiony na zachowanie pełnej historii ("data at rest") |
| Typ danych | Strumień zdarzeń emitowanych przez systemy | Sekwencja zdarzeń odtwarzających stan encji/agregatu |
| Technologie | Systemy Message Broker / Event Bus np. RabbitMQ, ActiveMQ, Apache Kafka, Wolverine | bazy NoSQL, KurrentDB, (dawniej EventStoreDB), Marten |
| Związek | Może transportować zdarzenia wygenerowane w ramach event sourcingu | Może wykorzystywać event streaming do publikacji zapisanych zdarzeń |
Podsumowując Event Streaming to sposób przesyłania i przetwarzania zdarzeń w czasie rzeczywistym, natomiast Event Sourcing to sposób utrwalania stanu aplikacji poprzez zdarzenia. Oba wzorce mogą się wzajemnie uzupełniać, ale nie są tym samym.
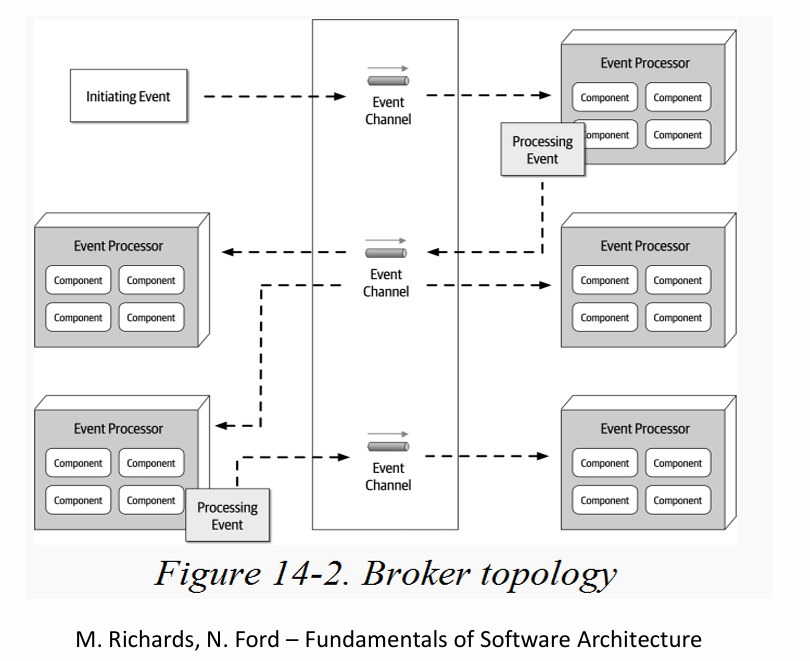
Przykład architektury opartej o strumieniowe przetwarzanie zdarzeń z zastosowaniem Brokera:
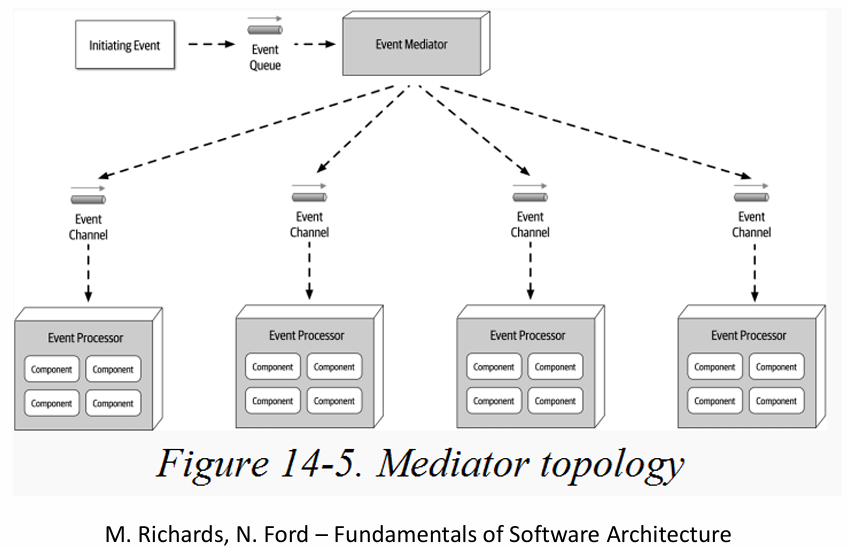
Przykład architektury opartej o strumieniowe przetwarzanie zdarzeń z zastosowaniem Mediatora:
Event Sourcing - funkcyjne podejście do zapisu
W programowaniu funkcyjnym unika się zmieninia stanu, w szczególności stanu globalnego. Uzyskuje się to głównie poprzez niemutowalne struktury danych oraz trzymanie się dyscypliny pisania czystych funkcji (są to funkcje pozbawione efektów ubocznych - jednym z nich jest właśnie zmiana stanu w szczególności globalnego; jest wiele innych efektów ubocznych, ale nie jest to przedmiotem tego artykułu).
Aktualnie systemy webowe implementuje się właśnie tak, aby serwer był możliwie jak najbardziej bezstanowy (każde żądanie przetwarzamy niezależnie). Niestety implementacja w 100% bezstanowego serwera Web jest praktycznie niemożliwa i to nie za sprawą tego, że jakiś komponent będzie przechowywał zmienny stan. Źródłem problemu jest baza danych, którą możemy porównać do dużego/globalnego mutowalnego bloba, który jest zmieniany przez wiele współbieżnie przetwarzanych transakcji/żądań.
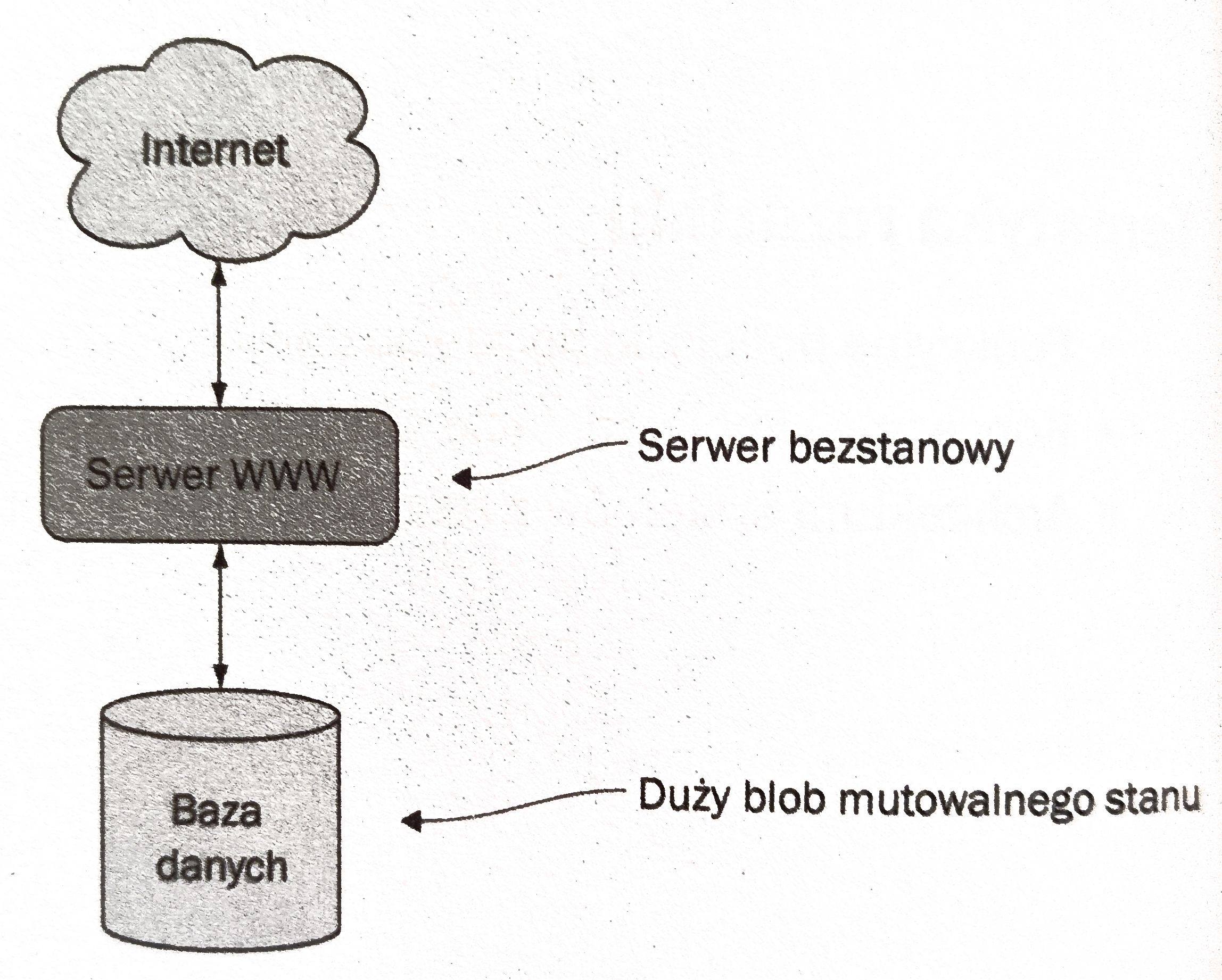
Event Sourcing przenosi założenia niemutowalności dotyczące struktur danych przechowywanych w pamięci aplikacji na niemutowalność rekordów w bazie danych (zdarzeń). Jest to tak zwane przechowywanie danych tylko przez dołączanie (append-only). Dzięki takiemu podejściu minimlizujemy problemy związane z wycofywaniem transakcji spowodowanym równoległym działaniem rozproszonych systemów. Łatwiej jest również skalować taki system o czym przekonamy się w dalszej części.
Dla porównania trydycyjnym zestawem funkcji w systemie bazodanowym są działania CRUD (Create, Read, Update, Delete) natomiast przy funkcyjnym podejściu i ES ograniczamy się do CRA (Create, Read, Append).
Event Sourcing - terminologia
W ES istnieje kilka podstawowych pojęć takich jak:
- zdarzenia (events),
- strumienie (streams),
- projekcje (projections),
- widoki (views),
- magazyn zdarzeń (event store),
- polecenia (commands).
Aby swobodnie poruszać się po tematyce ES należy je omówić i zrozumieć ich przeznaczenie.
Czym są zdarzenia?
Zdarzenie można zdefiniować w ES jako fakty dokonane - coś co się wydarzyło i nie mamy już na to wpłytu.
Cechy zdarzeń:
- prosta struktura - powinny przechowywać konkretny prosty zestaw danych odzwierciedlający to co stało się w systemie. Nie powinniśmy tworzyć za dużych zdarzeń. Jeśli dostrzegamy, że zdarzenie można podzielić na 2 kroki, które lepiej będą odzwierciedlały logikę biznesową to należy to zrobić. Nie ma konkrentej receptury określającej czy ciało zdarzenia jest za duże czy za małe, trzeba to wypracować w miarę obcowania ze wzorcem ES.
- niemutowalność - po wykonaniu operacji informacje zawarte w zdarzeniu nie mogą już zostać zmienione. Warto zatem przechowywać zdarzenia w kodzie w formie niemutowalnych struktur danych np. Java i C# w nowszysch wersjach oferują typ
record, który domyślnie jest typem niemutowalnym tj. po utworzeniu nie zmienimy już jego właściwości, będziemy musieli utrzowyć nowy obiekt przy każdej zmianie bazowego rekordu. - nazewnictwo w czasie przeszłym - Definiując zdarzenia powinniśmy używać czasu przeszłego w nazwach np. AccountCreated, AccountPersonalDataUpdated itp.
- mogą być różnie interpretowane - zdarzenia mogą być nasłuchiwane przez różne byty w systemie, w jedenym module konkretne zdarzenie może oznaczać aktualizację stanu agregatu, a w innym konieczność wysłania wiadomości email czy powiadomienia. Może się również zdarzyć, że zdarzenie nie ma żadnego odbiorcy a wykorzystane zostanie dopiero w przyszłości albo w ogóle.
// Przykład definicji zdarzeń w C#
public interface IDomainEvent;
public sealed record AccountCreated(
string Email,
DateTime CreatedAt) : IDomainEvent;
public sealed record AccountPasswordDefined(
string PasswordHash,
DateTime DefinedAt) : IDomainEvent;
public sealed record AccountPersonalDataUpdated(
string FirstName,
string LastName,
string PhoneNumber) : IDomainEvent;
public sealed record AccountConsentsApproved(
bool TermsAndConditions,
bool PrivacyPolicy) : IDomainEvent;
public sealed record AccountBlocked(
Guid BlockedBy,
DateTime BlockedAt) : IDomainEvent;Czym są strumienie?
Atomowo zgromadzone zdarzenia w systemie nie niosą za zobą wiele informacji jeśli nie da się ich ze sobą w logiczny sposób powiąząć. Zatem aby możliwym było odtworzenie aktualnego stanu encji/agregatu potrzebujemy mechanizmu, który jasno grupuje poszczególne zdarzenia ze sobą. Do tego służą właśnie strumienie.
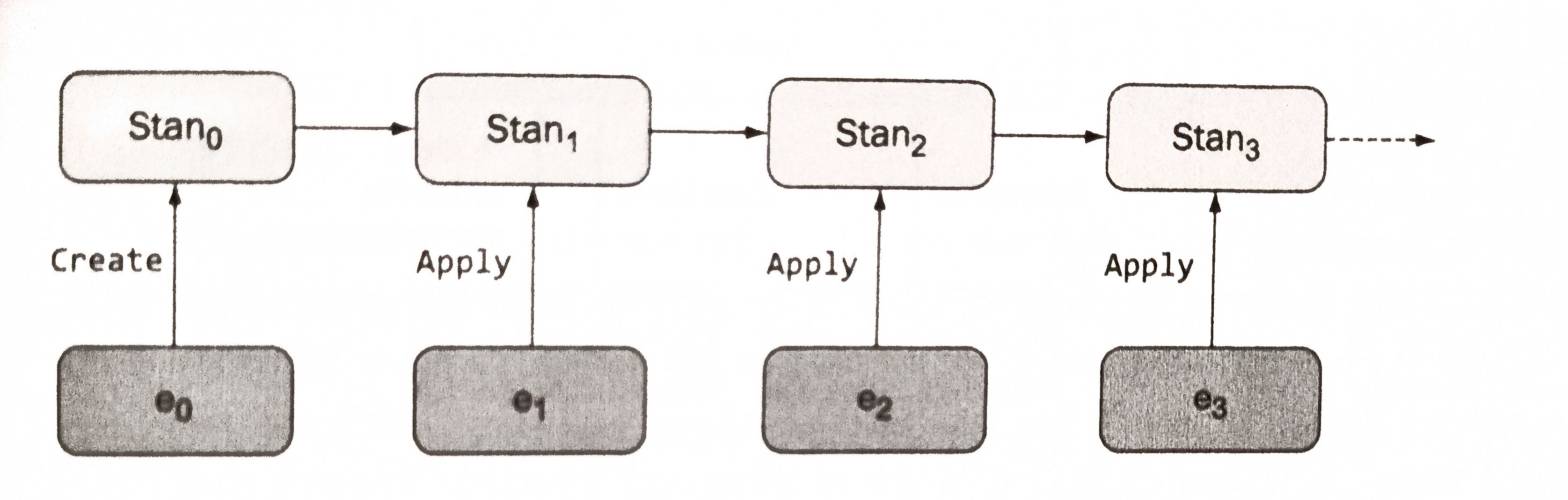
Strumień powinien mieć unikalny numer wersji np. version (to umożliwi określenie odpowiedniej kolejności zdarzeń; zwykle jest to zwykła liczba naturalna) oraz unikalny identyfikator skorelowany bezpośrednio z encją/agregatem, zatem stream_id = aggregate_id.
Każde ze zdarzeń musi posiadać identyfikator strumienia aby mogło zostać wykorzystane w agregacji zdarzeń, będącym sekwencyjnym przejściem po zdarzeniach z danego strumienia i aplikowaniem ich na klasę agregatu.
Czym są projekcje?
Projekcje w ES są mechanizmem umożliwiającym dodatkową obsługę wybranych przez nas zdarzeń. Projekcje mogą nasłuchiwać/obserwować konkretne strumienie zdarzeń, a następnie reagować na nie - wedle ustalonej przez nas procedury. System w ramach działania projekcji może koordynować pracę i wyzwalać różne operacje na bazie konkretnych zdarzeń. Możemy stosować ten mechanizm np. do:
- wysyłania wiadomości email w reakcji na zdarzenie,
- wyzwalania komendy systemowej,
- tworzenia zmaterializowanego widoku danych - tylko do odczytu.
Czym są widoki?
Modele widoków powstają w wyniku działania projekcji. Są obiektami danych gotowymi do wyświetlania po stronie klienta. Implementowane zwykle żeby poprawić wydajność systemu, widoki są materializowane i aktualizowane bezpośrednio po odnotowaniu zdarzenia w systemie.
Czym jest magazyn zdarzeń?
Stanowi on jądro ES. Magazyn zdarzeń to specjalizowane repozytorium danych odpowiedzialne za utrawalanie zdarzeń. W przeciwieństwie do tradycyjnych baz danych magazyn zdarzeń rejestruje każde zdarzenie jako niezmienny/niemutowalny (a także nieusuwalny) rekord. Gwarantuje to komplenty i dokładny zapis działań w systemie/aplikacji. Interfejs podstawowego magazynu zdarzeń powinien oferować:
- Odczyt sekwencji zdarzeń związanych z konkretnym agregatem
- Dodanie zdarzenia lub sekwencji zdarzeń do agregatu
Nie każda technologia nada się w roli magazynu zdarzeń. Prym wiodą tutaj bazy danych NoSQL (ang. Not only SQL), które oprócz tracydyjnego relacyjnego podejścia do danych oferują również inne formy przechowywania. W przypadku ES o danych będziemy zwykle myśleć jak o dokumentach, stąd dobrym wyborem będzie np.:
- MongoDB, Redis itd.
- Bazy relacyjne oferujące przechowywanie semi-strukturalnych danych (JSON, XML) np. PostgreSQL.
- Narzędzia Event Store - rozwiązania specjalnie przeznaczone do pełnienia roli magazynu zdarzeń. Takim narzędziem jest np. KurrentDB.
Ważne żeby magazyn zdarzeń spełniał kilka zasad:
- powinien tylko dodawać zdarzenia do tabeli,
- powinien zachować kolejność zdarzeń,
- powinien umożliwiać powiązanie agregatu ze zdarzeniem.
Przykład tabeli magazynującej zdarzenia
| SEQUENCE_ID | VERSION | STREAM_ID | TIMESTAMP (UTC) | EVENT_TYPE | DATA | METADATA |
|---|---|---|---|---|---|---|
| 100 | 1 | 8f9e2b6d-90a3-4c12-9e18-8cda5e7a1e73 | 2025-10-18T10:05:23.451Z | AccountCreated | { "email": "franciszek.dolas@event.com", "createdAt": "2025-10-18T10:05:23Z" } | { "correlationId": "c8aef390-6b62-4e15-8d4d-78a0a26d01e3" } |
| 101 | 2 | 8f9e2b6d-90a3-4c12-9e18-8cda5e7a1e73 | 2025-10-18T10:06:01.172Z | AccountPersonalDataUpdated | { "firstName": "Franciszek", "lastName": "Dolas", "phoneNumber": "123456789" } | { "correlationId": "a17df3a0-1c83-40b3-8a2a-ff239f85b993" } |
| 102 | 3 | 8f9e2b6d-90a3-4c12-9e18-8cda5e7a1e73 | 2025-10-18T10:06:45.889Z | AccountConsentsApproved | { "marketing": true, "termsAndConditions": true, "privacyPolicy": true } | { "correlationId": "b04e1bcf-88ef-4f91-b4c0-9f8a1d379c84" } |
Podstawowa/przykładowa implementacja agregatu w ES
public interface IAggregateRoot
{
public Guid Id { get; }
public void Evolve(IDomainEvent @event);
};
public class Account : IAggregateRoot
{
public Guid Id { get; private set; }
public string Email { get; private set; }
public string FirstName { get; private set; }
public string LastName { get; private set; }
public string PhoneNumber { get; private set; }
public AccountStatus Status { get; private set; }
public void Evolve(IDomainEvent @event)
{
switch (@event)
{
case AccountCreated accountCreated:
Apply(accountCreated);
break;
case AccountPasswordDefined passwordDefined:
Apply(passwordDefined);
break;
case AccountPersonalDataUpdated personalDataUpdated:
Apply(personalDataUpdated);
break;
case AccountConsentsApproved consentsApproved:
Apply(consentsApproved);
break;
case AccountBlocked accountBlocked:
Apply(accountBlocked);
break;
default:
break;
}
}
private void Apply(AccountCreated e)
{
Id = Guid.CreateVersion7();
Email = e.Email;
Status = AccountStatus.RequireActivation;
}
private void Apply(AccountPasswordDefined _)
=> Status = AccountStatus.Activated;
private void Apply(AccountPersonalDataUpdated e)
=> (FirstName, LastName, PhoneNumber) = (e.FirstName, e.LastName, e.PhoneNumber);
private void Apply(AccountConsentsApproved _) { }
private void Apply(AccountBlocked _)
=> Status = AccountStatus.Blocked;
}
public enum AccountStatus
{
RequireActivation,
Activated,
Blocked
}Ta podstawowa implementacja już umożlia nam sekwencyjne zaaplikowanie zdarzeń na korzeń agregatu
// Zdarzenia wczytujemy za pomocą EventStore
// W ramach uproszczenia zakładamy, że dostaliśmy już sekwencję zdarzeń z magazynu
List<IDomainEvent> events =
[
new AccountCreated("franciszek.dolas@event.com", DateTime.UtcNow),
new AccountPersonalDataUpdated("Franciszek", "Dolas", "123456789"),
new AccountPasswordDefined("hash", DateTime.UtcNow),
new AccountConsentsApproved(true, true)
];
// Tworzymy agregat/encję i aplikujemy na niej sekwencję zdarzeń
var account = new Account();
events.ForEach(e => account.Evolve(e));
Console.WriteLine($"Account owner: {account.FirstName} {account.LastName}");
Console.WriteLine($"Account status: {account.Status}");
// wyświetla -> Account owner: Franciszek Dolas
// -> Account status: ActivatedTIP
Na pierwszy rzut oka wydawać się może, że takie podejście prowadzi do generowania dużej ilości nadmiarowego kodu, ale w rzeczywistoście jest to opłacalne. Taki sposób pisania agregatów powoduje, że najważniejsza logika biznesowa znajduje się w centralnym miejscu encji/agregatu opisując tym samym jej zachowanie. Dzięki temu model domenowy nie jest anemiczny. To też ułatwia ich testowanie (w większości przypadków nie będzie potrzebne tworzenie serwisów/usług i specjalizowanych repozytoriów do zarządzania encjami - wszystko będzie zapisane od razu w metodach agregatów).
Architektura systemów z zastosowaniem event sourcingu
Przepływ danych w systemie opratym na zdarzeniach różni się od tradycyjnych rozwiązań, w których opieramy się o zestaw operacji CRUD. W klasycznym podejściu mamy doczynienia z encjami, które są tworzone, pobierane, modyfikowane i wysyłane do klientów. Przekształcenia pomiędzy encją (rekordami) z bazy a finalnym zestawem danych (finalnym DTO) są zwykle małe. Wynikowa zwrotka z serwera zawiera podobny zestaw informacji do tego odczytanego z bazy.
W systemach opartych o Event Sourcing wygląda to inaczej. To co przechowujemy to zdarzenia, lecz użytkownicy nie chcą widzieć surowego dziennika zdarzeń a sensowny zestaw danych. Z tego powodu system wykorzystujący wzorzec projektowy ES należy podzielić na dwie części:
- Stronę poleceń - odpowiada za zapisywanie danych (walidacja poleceń użytkownika, dodawanie zdarzenia, propagowanie zdarzenia dalej w systemie).
- Stronę zapytań - głównym zadaniem jest odczyt danych i zwrócenie ich do użytkownika w odpowiedniej formie. System wykorzystuje w tym celu przygotowane wcześniej modele widoków, czyli gotowe do wyświetlenia zestawy danych, powstające na bazie projekcji sekwencji zdarzeń.
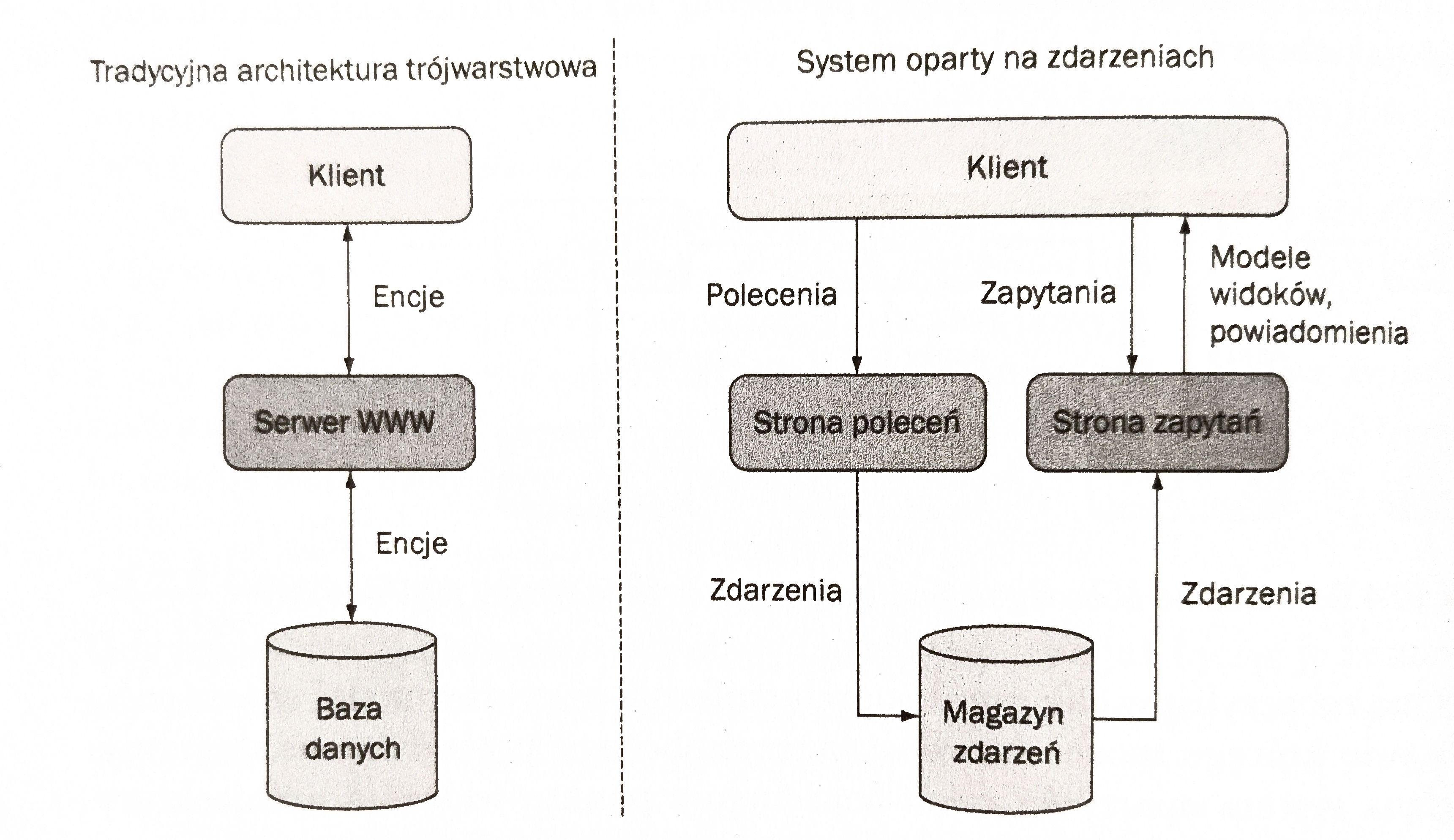
Widać zatem, że ES idzie naturalnie w parze ze wzorcem CQRS (ang. Command Query Responsibility Segregation).
CQRS
Wzorzec ten polega na oddzieleniu od siebie zapytań i poleceń co pozwala na niezależne rozwiązywanie problemów skalowalności w każdej z części.
- Polecenia - zmieniają stan systemu i nie muszą zwracać zestawu danych (zwykle wynikiem pozytywnej operacji będzie pusta krotka
(),Unit). - Zapytania - nie zmieniają stanu ale zwracają dane.
Separacja może być implementowana w różnych konfiguracjach i na różnych poziomach:
- kodu źródłowego - oddzielny moduł/repozytorium dla zapytań i odzielny moduł dla poleceń.
- wdrożenia - oddzielne usługi/serwisy/aplikacje do zapisywania infomacji i ich odczytywania. To pozwala niezależnie skalować poszczególne strony, ale również umożliwi stworzenie obu wdrożeń z wykorzsytaniem różnych technologii (np. do odczytu wydajne i lekkie zapytania; do zapisu cięższe ale niezawodne narzędzia).
- magazynu danych - odzielna baza/schema dla odczytu i oddzielna baza do zapisywania zmian.
Zatem system oparty o ES możemy tworzyć w różnych konfiguracjch. Np.
- jedna baza danych; jedna monolityczna aplikacja.
- dwie bazy danych (odczyt i zapis; mogą być różne technologie np. do odczytu NoSQL a do zapisu PostgreSQL); dwie niezależnie skalowalne usługi (zapis i odczyt).
- jedna baza ale z podziałem na 2 schemy; wiele modularnych monolitów.
- itp.
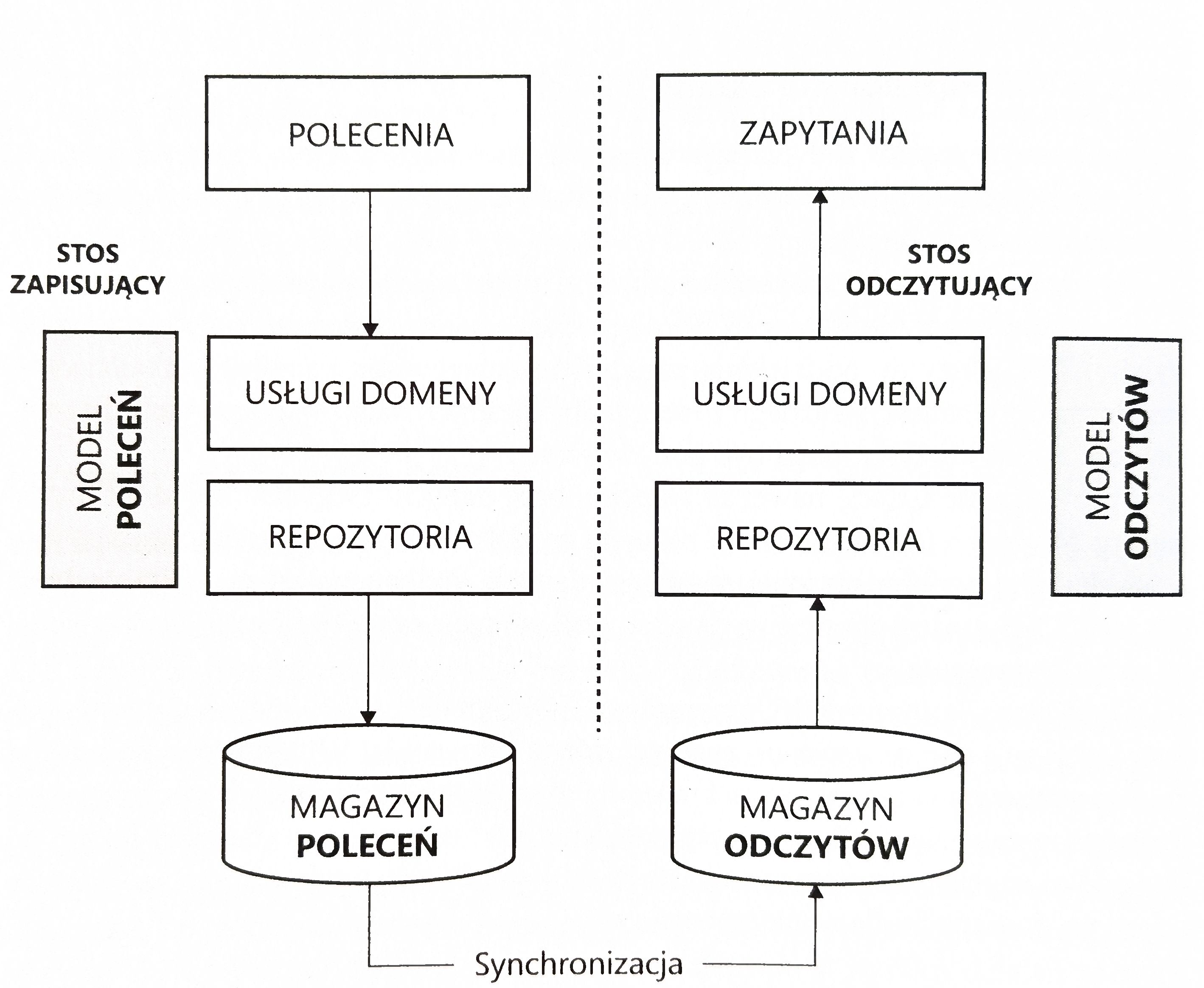
TIP
Warto wspomnieć o tym, że synchronizacja może być dosyć kłopotliwa. Można to implementować na różne sposoby. Jako przykład można wspomnieć o Martenie, który radzi sobie z tym za pomocą Async Projections Daemon, który dba o odpowiednie przetworzenie i aktualizację liczników przetworzonych/obsłużonych zdarzeń.
Mediator
Innym wzorcem, który często towarzyszy ES, jest wzorzec mediatora, który ułatwia definiowanie przepływu komend i zapytań w systemie.
Mediator działa jako scentralizowany hub koordynujący i sterujący interakcjami pomiędzy komponentami, zamiast bezpośredniej komunikacji pomiędzy tymi składnikami. Mediator przekierowuje polcecenia i zapytania do odpowiednich uchwytów albo modułów. To jeszcze bardziej ułatwia separację pomiędzy zapytaniami a poleceniami.
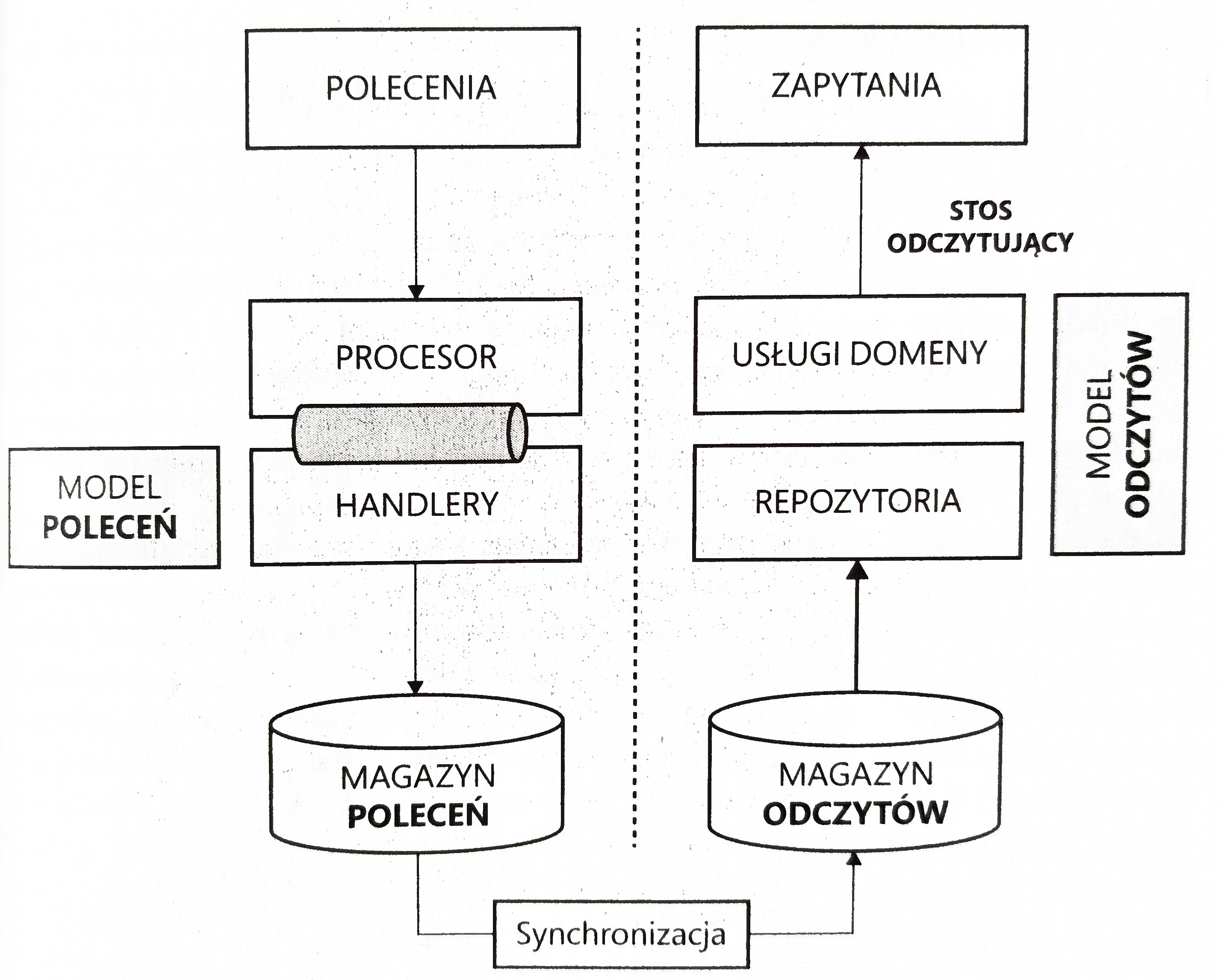
Procesorem może być biblioteka realizująca wzorzec mediatora, nasza właśna implementacja wzorca albo bardziej złożone narzędzie w postaci usługi kolejki.
Zalety Event Sourcingu
- Dziennik audytu (audit log) - rejestrowanie każdego zdarzenia biznesowego umozliwia nam bardzo łatwą implementację dziennika audytu wystarczy do zdarzeń dodać drobny zestaw metadanych np.
Guid UserId, Timestamp When, Guid CorrelationId, a to pozwoli na szybki i wydajny wgląd w hisotrię edycji danego agregatu/encji. Ta cecha może być szczególnie przydatna przy systemach gdzie audyt jest wymaganiem funkcjonalnym, przy ES mamy go praktycznie za darmo. - Odtwarzanie historycznego stanu - rejrestrowanie każdego zdarzenia biznesowego pozwala również na odtwrzanie konkretnego historycznego stanu systemu (nie zawsze jest to łatwe, ale mamy przynajmniej taką możliwość; to czy będzie nam łatwo odtwarzać stan będzie zależało od naszej implementacji i złożoności modelu informacyjnego - im więcej zależności i efetów ubocznych tym ciężej będzie odtworzyć stan).
- Brak utraty danych - systemy oparte na ES rejestrują każdą operację biznesową, więc żadne informacje nie zostaną utracone/nadpisane.
- Diagnostyka - w systemach rozproszonych (a zwykle ES do takich należą) analizowanie i odtwrzanie błędów bywa kłopotliwe. ES przychodzi z pomocą zapewniając odnotowywanie operacji biznesowych również w sytuacjach niepowodzenia. Wiele implementacji stosuje podejście odnotowywania zdarzeń nagrobków (
tombstone). Działa to na zasadzie odnotowywania zdarzenia typutombstonew tabeli zdarzeń w momencie niepowodzenia transakcji. Takie zdarzenia nadal przechowują metadane, które umożliwają dojście do przyczyny błędu. Analiza błędów może być również związana z błędną obsługą systemu przez użytkowników. Przykładem może być jeden z systemów wdrożonych produkcyjnie, gdzie urzędnicy twierdzili, że pewna funkcjonalność nie działa. Sekwencja zdarzeń pomogła mi w pełni odtworzyć kroki realizowane przez urzędników i dojść do tego, że okłamują klienta, ponieważ widać było w zdarzeniach wykonywanie kompletnie innych operacji niż te deklarowne. Inny przykład - w systemie dochodziło czasami do błędów które ciężko było odtworzyć w środowiku testowym, prześledzenie sekwencji zdarzeń z produkcyjnego wdrożenia pozwoliło na znalezienie przyczyny błędu. - Dodatkowe źródło informacji - same zmiany stanów poszczególnych encji mogą być traktowane jako cenna informacja, która można wykorzystać w raportach i analizie. Np. ktoś dodaje produkt do koszyka a nastepnie go usuwa - mamy rejestrację każdego z tych zdarzeń + odstępy czasu, całość można analizować i dochodzić dlaczego ktoś zrezygnował z zakupu.
- Rozszerzalność reprezentacji biznesowej - w ES ograniczamy się jedynie do dodawania nowych zdarzeń, więc nic nie stoi na przeszkodzie aby dodawać również nowe typy zdarzeń reprezentujące nowe operacje biznesowe (nowe funkcjonalności), dzięki temu dodawanie i modyfikowanie scenariuszy i reguł biznesowych jest możliwe i względnie proste.
- Modularność i skalowalność - stosowanie wzorca ES w naturalny sposób będzie wymuszał na programistach wiekszą separacje w kodzie źródłowym (podział na komendy i zapytania). SoC (ang. Separation of Concerns) to bardzo porządana cecha projektów, ponieważ tworzmy kod lepiej podzielony i bardziej reużywalny. Dodatkowo większy podział może również zostać zaimplementowany na poziomie bazy danych np. oddzielny magazyn dla zdarzeń; oddzielny dla odczytu. Gdy dodamy do tego jeszcze dobrze zaimplementowany wzorzec CQRS to modularny monolit może bez problemu skalować się horyzontalnie, ale również możemy podzielić go na mniejsze serwisy (np serwis odpowiedzialny za odczyt danych i oddzielny do obsługi poleceń dodających zdarzenia).
Wady Event Sourcingu
- Stosunkowo złożony - ES wymaga zasadniczej zmiany w myśleniu o projektowanym modelu informacyjnym i architekturze systemu. Inaczej modelujemy informacje/dane w klasycznym obiektowo-relacyjnym podejściu (np. z wykorzystaniem diagramów związków encji czy UML), a inaczej tworząc agregaty/encje powstające na bazie przetwarzania sekwencji zdarzeń. To wymaga wprawy i obycia ze wzorcem. Zatem ES może wprowadzaić dodatkową złożoność w czasie tworzenia oprogramowania, jego testowania i późniejszym utrzymaniu. Może być stosunkowo trudno wdrożyć kogoś do projektu opartego o ES, w szczególności gdy nie miał on wcześniej styczności z tym wzorcem.
- Ewolucja struktur - w ES łatwo dodaje się nowe elemnty do systemu, ponieważ nie musimy migrować schematów danych, a jedynie odpowiednio dodawać nowe zdarzenia i właściości. Niestety sprawa nie jest już taka kolorowa, gdy okazuje się, że popełniliśmy jakiś błąd na wczesnym etapie projektu i teraz trzeba wprowadzić breaking change w modelu informacyjnym. Np. bazowo modelowaliśmy asocjacje pomiędzy agregatami jako 1 do 1, a nowe wymogi biznesu wymuszają aby połączenie było 1 do N albo N do M. Pojawia się problem zachowania wstecznej kompatybilności z isntiejącymi historyczymi danymi (są w końcu niemutowalne, więc nie możemy ich zmienić) i zmigrowaniem rozwiązania na nowe. Istnieje wiele różnych strategii pomagających rozwiązać tego typu problemy, ale niestety powoduje to, że zadanie, które w klasycznym podejściu może okazać się trywialne, nie jest takie proste w ES, właśnie przez potencjalne złamanie wstecznej kompatyblności, o którą musimy dbać. To wymaga bardzo starannego planowania.
- Synchronizowanie/Spójność danych - przez to, że ES zwykle realizowany jest w systemach o architekturze rozproszonej mogą pojawiać się problemy z utrzymaniem spójnych danych w poszczególnych modelach odczytu. Np. system zrealizował jakieś polocenie i wyzwolił synchronizację danych z usługą odpowiadającą za odczyt, jeśli operacja synchronizacji się nie powiedzie, to istnieje duża szana utraty spójności danych pomiędzy atomowymi zdarzeniami będącymi głównym źródłem prawdy a danymi z widoków, które wysyłane są do klienta (to może generować różne błędy po stronie klienckiej). W takich sytuacjach powinno się podejmować dodatkowe kroki np. powtarzanie operacji synchronizacji n razy albo zastosowanie wzorców kompensujących np. SAGA - czyli wykonanie dodatkowych kroków wyrównujących niespójnosć danych. To sprawia, że utrzymanie systemu może być momentami trudniejsze.
- Rozmiar magazynu zdarzeń - jeśli nasz system rejestruje miliony zdarzeń, to na pewnym etapie baza danych może puchnąć szybciej i zajmować więcej przestrzeni w porównaniu z tradycyjnym podejściem.
- Usuwanie danych wrażliwych - w wielu produkcyjnych systemach prędzej czy później będziemy mieli styczność z danymi wrażliwymi (np. dane osobowe) użytkowników. Zgodnie z RODO musimy zapenwić możliwość usuwania tych informacji. Przez koncepcję append-only i niemutowalność zdarzeń w ES nie jest to takie proste. Usunąć zdarzenia z pewnością nie możemy bo zakłóci to spójność danych w magazynie zdarzeń (może to generować problemy przy sekwencyjnym przechodzeniu przez zdarzenia). Jedyną opcją w tym przypadku jest anonimizacja i maskowanie istniejących danych w zdarzeniach. To z kolei nakłada dodatkową złożoność łamiącą podstawowe zasady ES, ale gwarantuje usuwanie danych. Zdarza się, że biblioteki ułatwiające implementację wzorca ES np. Marten wspierają anonimizacje/maskowanie danych w zdarzeniach (dodano to w 7 wersji Martena), ale zwykle sami będziemy musieli zaimplementować taki mechanizm.
Kiedy warto używać ES
- Gdy zależy nam na hisotrii zmian i audycie - jeśli jednym z wymagań nakładanych na system jest możliwość dokładnego śledzenia co i kiedy zaszło, to ES jest wręcz naturalnym wyborem.
- Gdy domena skupia się na procesach - jeśli w domenie dostrzegamy modele, które będą podlegały jakimś procesom i zmieniały swój stan w czasie zgodnie z konkretnymi regułami, to warto iść w ES.
- Gdy domena jest zmienna i ewoluuje - jeśli jesteśmy małym zespołem dobrze zapoznanym z modelem ES, to łatwiej będzie (w szczególności w fazie pracy nad MVP) zmieniać model naszego systemu informacyjnego i go rozwijać.
- Gdy zależy nam na możliwości odtwarzania historycznego stanu
Kiedy NIE warto używać ES
- Gdy nasz system to prosty CRUD - jeśli domena biznesowa jest prosta i nie wymaga skomplikowanych operacji to ES stanowi zbyt duży kaliber na tego typu aplikację. Czyli jeśli system to zwykły Content Management System (CMS) to ES jest nadmiarowe.
- Poza częścią domenową projektu - ES jest opłacalny tylko w ramach warstwy domenowej. Inne miejsca takie jak konfiguracja (WebAPI - prezentacja), dzienniki aplikacji (infrastruktura i Cross-cutting concern - różne warstwy) nie nadają się pod ES.
- Zespół nie ma doświadczenie z ES - jeśli w zespole tylko jedna osoba zna ES a reszta nigdy o takim podejściu nie słyszała, to tworzenie systemu w oparciu o ES jest ryzykowne.
- Gdy aktualne rozwiązania są skuteczne - jeśli obecne rozwiązanie działa i spełnia zapotrzebowania klienta to nie ma sensu komplikować go na siłę przy pomocy ES.
Bibliografia
- "Czysta architektura w .NET - Dino Esposito 2024" str. 16-18 (Dodawanie Event Sourcing) i str. 242-249 (Architektura magazynu danych)
- "Programowanie funkcyjne w języku C# - Enrico Buonanno" str. 237-263 (Event Sourcing: funkcyjne podejście do zapisu)
- Dokumentacja biblioteki Marten (Understanding Event Sourcing with Marten) - https://martendb.io/events/learning.html
- Artykuł "CQRS i Event Sourcing - czyli łatwa droga do skalowalności naszych systemów" - https://bulldogjob.pl/readme/cqrs-i-event-sourcing-czyli-latwa-droga-do-skalowalnosci-naszych-systemow
- Artykuł "When not to use Event Sourcing?" - https://event-driven.io/en/when_not_to_use_event_sourcing/?utm_source=event_sourcing_net
- Artykuł "What is event streaming?" - https://www.ibm.com/think/topics/event-streaming
- Artykuł "Event storming" - https://en.wikipedia.org/wiki/Event_storming